EndoNuke
EndoNuke is a dataset dedicated to train the models for nuclei detection in endometrium samples. It consists of more than 1600 image tiles of physical size 100μm x 100 μm with the annotated nuclei locations as keypoints. The nuclei are also classified with one of three labels: stroma, epithelium, other. The process of the dataset annotation is described in our paper (currently under review). The supplementary code, as well as masks generating scripts are available at the supplementary repository.
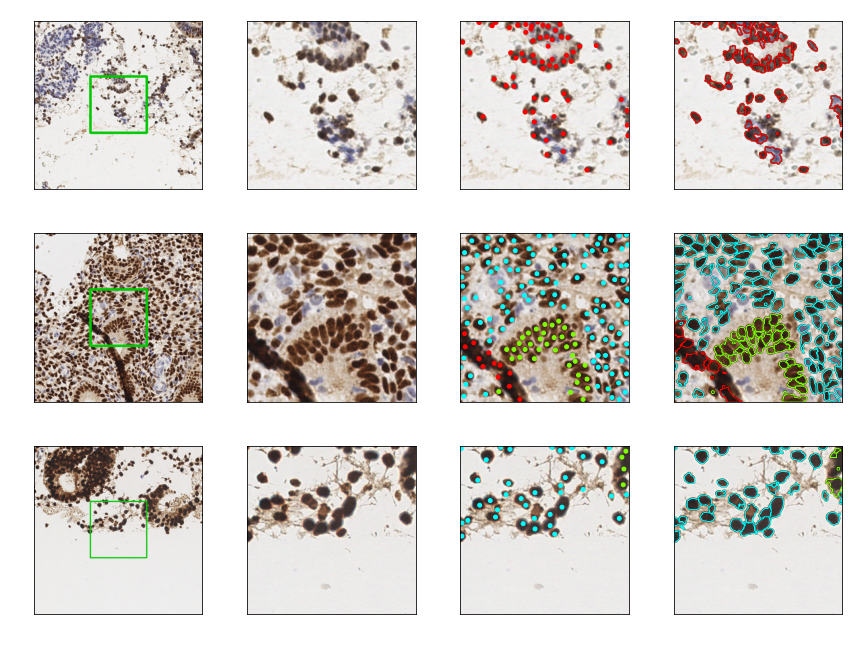
Dataset structure
The dataset itself is placed in the directory data/dataset. It is organized in the following manner:
- The directory
data/dataset/imagescontains all dataset images (tiles). There are no subdirectories here. Each image has a unique numeric filename, which can be treated as image_id. - The directory
data/dataset/labelscontains the annotations. It has two subdirectories:bulkandagreement. bulkdirectory contains most of the annotations, the subdirectories (ptg1,stud3...) correspond to different annotators. In these dirs the annotations are contained. The annotations aretxtfiles with the same numeric names as for the corresponding images files.agreementdirectory contains the annotations from the agreement studies. It has three subdirectories:prior,hiddenandposterior, which correspond to different studies (the details are in the paper). Each of these subdirs also have the subdirectories, corresponding to different experts (ptg1,stud3...). In these dirs the annotations are contained. The annotations aretxtfiles with the same numeric names as for the corresponding images files.- The direcotry
data/dataset/images_contextcontains all the context images. There are no subdirectories here. These images are 9 times larger than the labeled images. The filenames for the context images are the same, as for the labeled images. There are no annotations for these images. - The directory
data/dataset/metadatacontains images metadata injsonformat. There are no subdirectories here. The filenames for the context images are the same, as for the labeled images. - The directory
data/dataset/file_listscontains the files with lists of the relative filepaths for the bulk of the dataset and for the agreement studies. It has the same structure asdata/dataset/labelsdirectory. These lists are needed to initializePointsDataset()instance (from here). Each dir on the lower level has two files:images.txtwith the filepaths to images andlabels.txtwith the filepaths to annotations. The path on the first line ofimages.txtcorresponds to the path on th first line oflabels.txt, the second one to the second one and so on.
Annotation format
The annotations are contained in the text files with the names formatted as.txt x_coordinate, y_coordinate, class_label. The coordinates are given in pixels with zero indexing. The classes are:
- 0 for the stroma
- 1 for the epithelium
- 2 for the the other nuclei
The example of the annotation file is below:
11 3 0
5 26 2
20 29 0
29 56 1
...
Master ymls
Master ymls are placed in the directory data/master_ymls and help to organize data access to the dataset. They contain relative paths to files with lists of paths to images and label (from data/dataset/file_lists). There are several master_ymls for different purposes:
everything.yamlhas the paths to all the dataset images and annotations. If these files lists are used, the tiles from agreement studies will be accessed multiple times.unique.yamlhas all the paths to images and annotations from the bulk of the dataset and the paths to images and annotations for agreement studies from theptg1expert. If these files lists are used, every tile will be accessed a single time.bulk.yamlhas all the paths to images and annotations from the bulk of the dataset.agreement.yamlhas all the paths to images and annotations for the agreement studies. If these files lists are used, the tiles from agreement studies will be accessed multiple times.hidden_agreement.yaml,preliminary_agreement.yamlandposterior_agreement.yamlhas all the paths to images and annotations for different agreement studies.
Tiles filtering
As mentioned in the paper, some tiles were manually filtered to ensure the presence of unordinary cases in the dataset. However, this process affects the feature distribution, which can lead to the bias in the model quality estimation. If a researcher wants to address this issue, it is possible to separate filtered and non-filtered data using images filenames (which are the same as images ids).
Images with the ids less or equal to 1600 were randomly sampled from the slides and then manually filtered to form the tasks for the annotation. Images with the ids greater than 1600 were filtered only with the background detection script before forming the tasks.
Downloads
You can download the dataset here.

This work is licensed under a Creative Commons Attribution 4.0 International License.
Team
IT team:
Anton Naumov
Andrey Ivanov
Egor Ushakov
Evgeny Karpulevich
Medical team:
Tatiana Khovanskaya
Alexandra Konyukova
Konstantin Midiber
Nikita Rybak
Maria Ponomareva
Alesya Lesko
Ekaterina Volkova
Polina Vishnyakova
Sergey Nora
Liudmila Mikhaleva
Timur Fatkhudinov